Speech Recognition
Speech Recognition and Say - Take a Snap assets are available in the Lens Studio Asset Library. Import either of asset packages to your project and place the included prefab in the Scene Hierarchy.
Speech Recognition examples demonstrate how you can use the Voice ML to incorporate transcription, live transcription, keyword detection, voice navigation command detection and System Command detection into the Lenses with almost no code.
SpeechRecognition script attached to the Speech Recognition [EDIT_ME] scene object is the main controller of both examples. Let's take a look at its inputs.
Make sure to disable the settings you don't need and delete all the unused setting scripts, such as Speech Contexts, Keyword Parent or Command Handler.
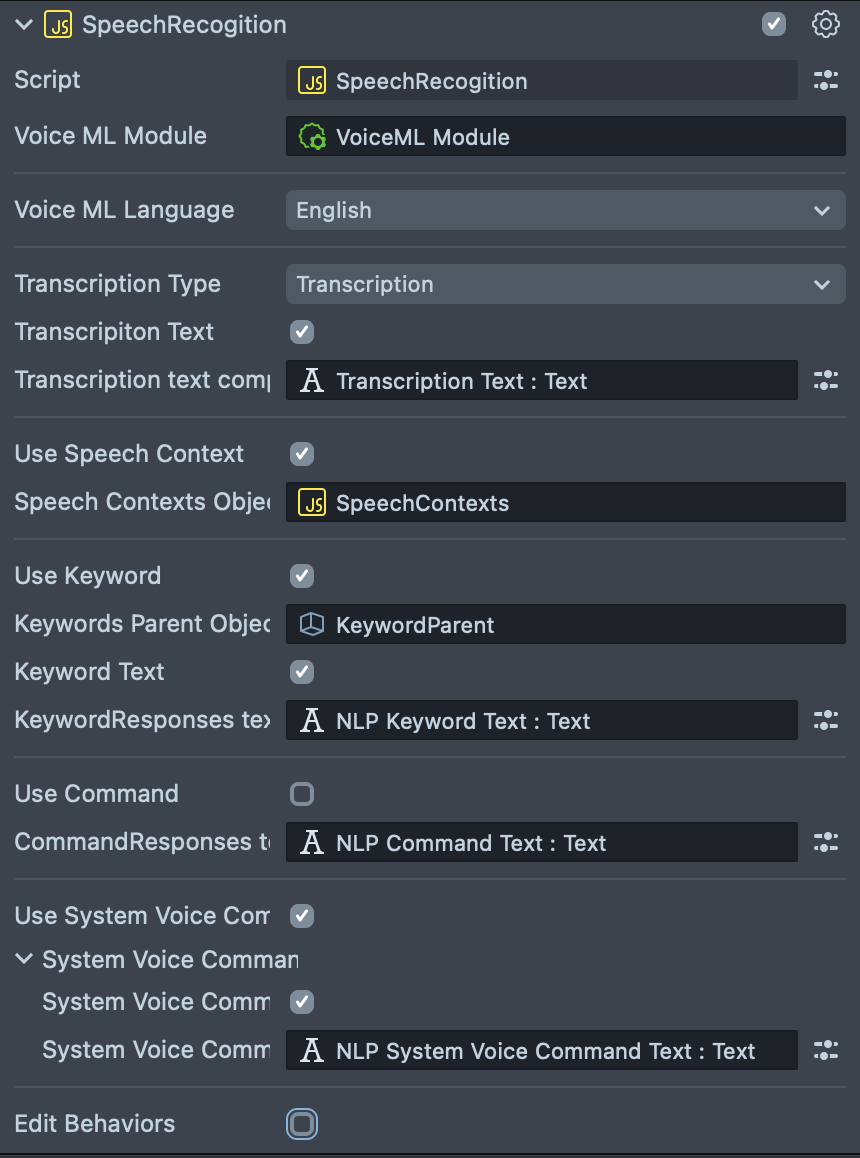
- VoiceML Module - reference to the Voice ML Module asset.
- Voice ML MlLanguage - allows to set language to use.
Transcription
- Transcription Type - a type of transcription, can take one of the values:
- Transcription - final transcription.
- Live Transcription - live and slightly less accurate transcription before we get the final, more accurate transcription.
- Transcription Text: if enabled transcription result can be displayed on a Text component.
- Text Component: Text component to set output text to.
Speech Context
Incorporating speech contexts into transcription can enhance the likelihood of accurately capturing specific words, particularly those that are less common and not readily recognized by Snap. By increasing the boost value, the probability of the desired words appearing in the transcription is enhanced. This feature is beneficial for scenarios that require precise transcription of rare words.
- Use Speech Context: if enabled, allows to set Speech Contexts object.
- Speech Contexts Object: reference to a Speech Context script.
Add New Phrase
With Speech Context script we can add words to the phrases and set a boost value for the phrases. To add a new word, click on the Add Value field and input a new word you want to add.
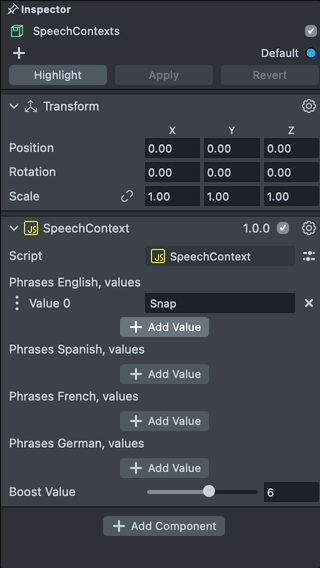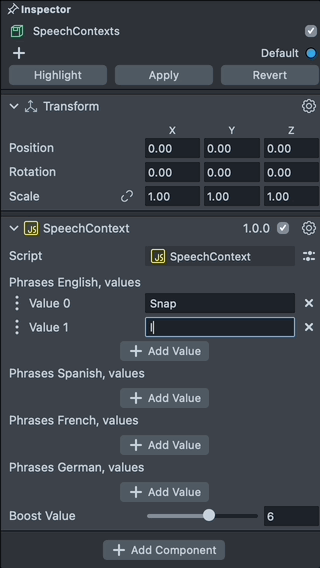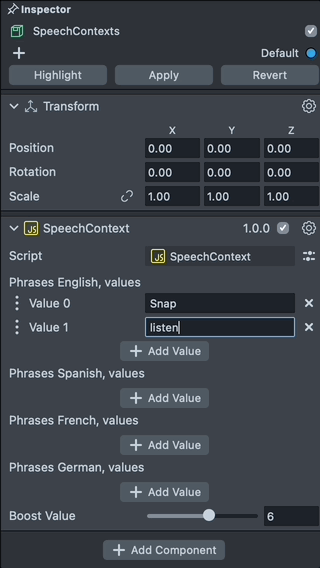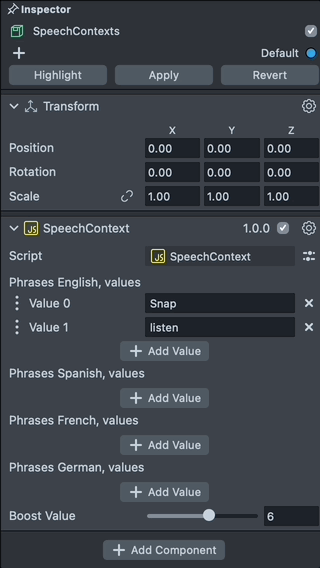
Notice here the phrases should be made of lowercase a-z letters. The phrases should be within the vocabulary.
Out of Vocabulary
When an OOV(out of vocabulary) phrase is added to the Speech Context, the Voice Event - On Error Triggered will be triggered. We will see the error message in the Logger. Here we take a random word az zj as an example.
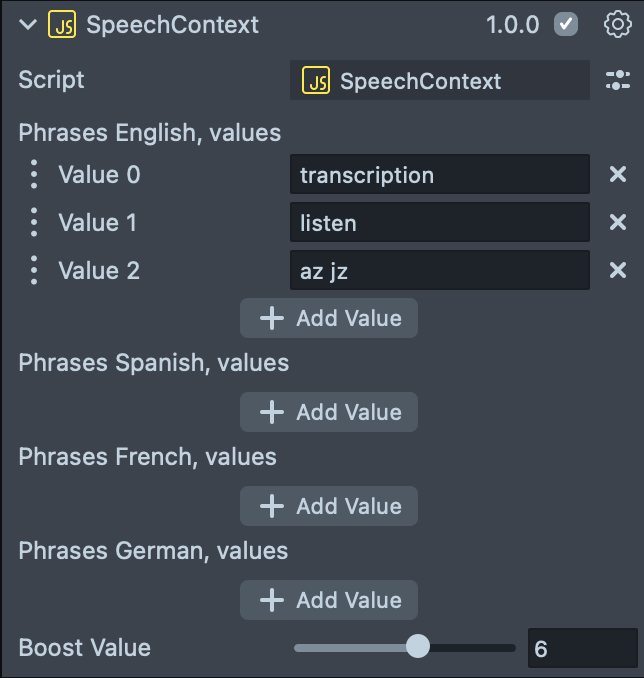
Try this by resetting the Lens in the Preview Panel, then speaking with the Microphone button enabled. We can then see the error message in the Logger.

Add New Speech Context Object
Or we can add a new Speech Context script with a different boost value.
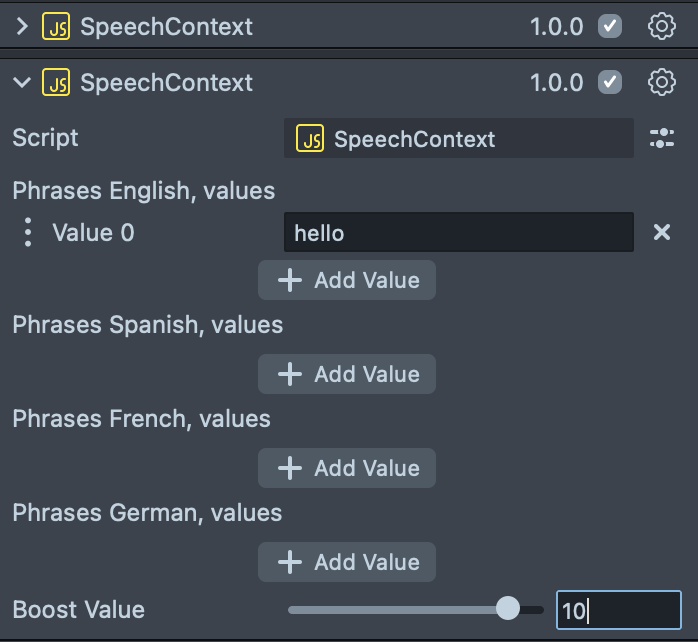
The range for boost value is from 1-10, we recommend you'll start with 5 and adjust if needed (the higher the value is, the more likely the word will appear in transcription)
Voice Events and Behavior Script
For each Voice Event Callback, we can assign multiple Behavior Scripts.
-
Edit Behaviors - allows to add behavior script responses for different voice events.
- Debug : if enabled prints out detected voice events in the Logger panel.
For each voice event, multiple instances of Behavior script can be set: - On Listening Enabled: Behavior scripts triggered when the microphone is enabled. - On Listening Disabled: Behavior scripts triggered when the microphone is disabled. - On Listening Triggered: Behavior scripts triggered when changed back to listening mode. - On Error Triggered: Behavior scripts triggered when there is error in the transcription. - On Final Transcription Triggered: Behavior scripts triggered when it's a full result, or partial transcription. - On Command Detected: Behavior scripts triggered when any command is detected.
In Lens Studio Preview the microphone button is not simulated on the Screen. When we reset the preview, once the Speech Recognition is initialized, On Listening Enabled will be triggered automatically. To learn how to use the microphone button, try to preview the Lens in Snapchat! Please check the details in Previewing Your Lens.
Keyword Detection
Now that you have learned how to use the basic transcription let's take a look at keyword detection section of a Speech Recognition script. It allows to trigger behaviors based on different keywords detected from the transcription!
- Use Keyword: allows the use of keyword detection.
- Keywords Parent Object: reference to the scene object that is a parent of all the
Keywordscripts. - Keyword Text: if enabled allows to output detected keyword to a Text component.
- Keyword Responses Text: Text component to use.
Keyword Script
In order to add new keyword let's create new scene object under the KeywordParent object and add Keyword script to it.
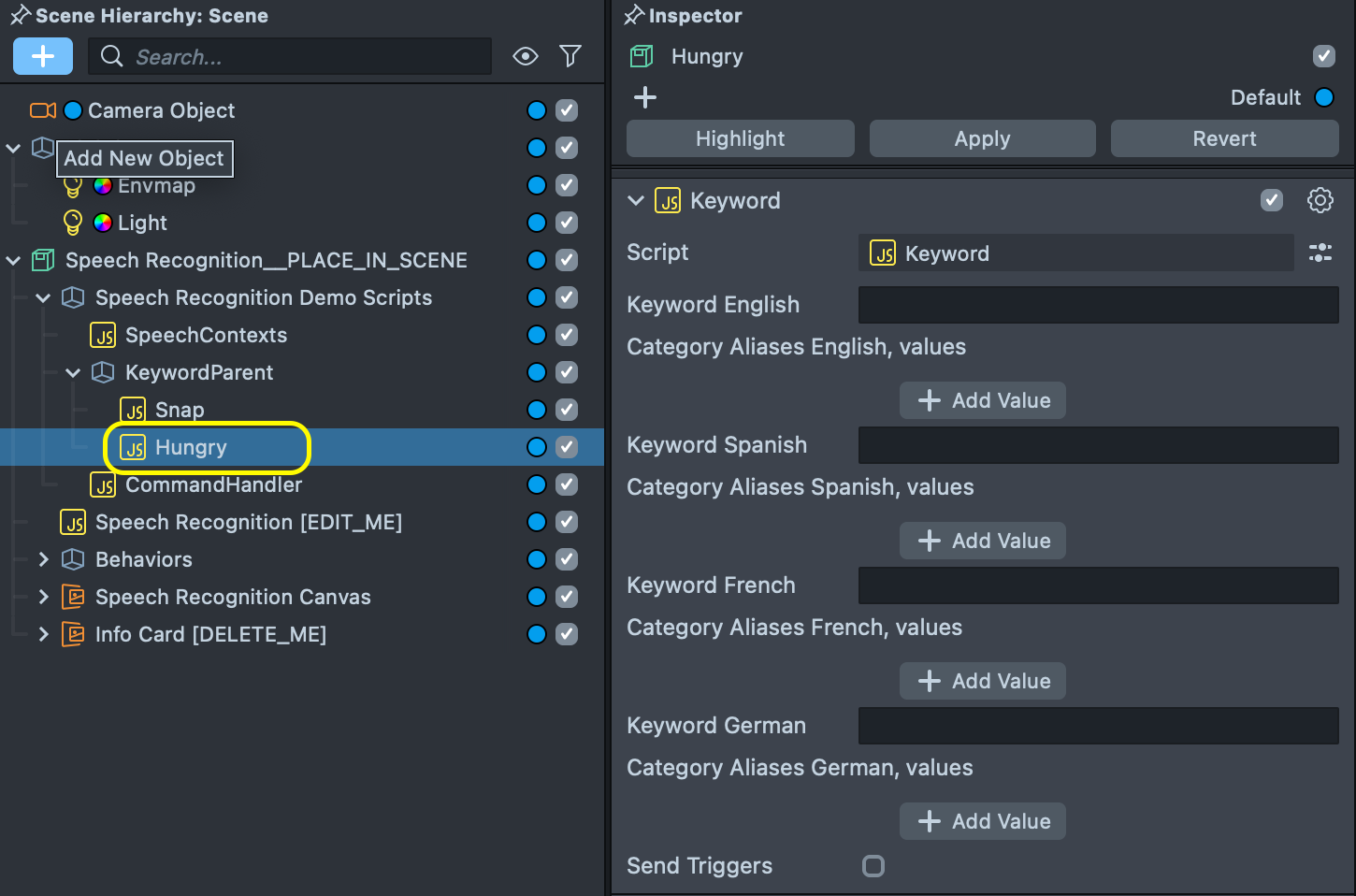
Don't forget to boost your keywords using Speech Context option.
Keyword script allows us to configure certain settings, such as:
- Keyword for each supported language.
- Category Aliases for each language. Aliases allow to expand the subset of words that should return certain keyword if needed to serve a specific Lens experience.
- Send Triggers checkbox - allows to specify a list of Behavior scripts to trigger if keyword is detected.
When using keyword detection, VoiceML will try to try to mitigate small transcription errors such as plurals instead of singular or similar sounding words (ship/sheep etc), instead, use multiple keywords to think about how different users might say the same thing in different ways like “cinema”, “movies”, “film”.
Next screenshot shows possible configuration for a Hungry keyword.
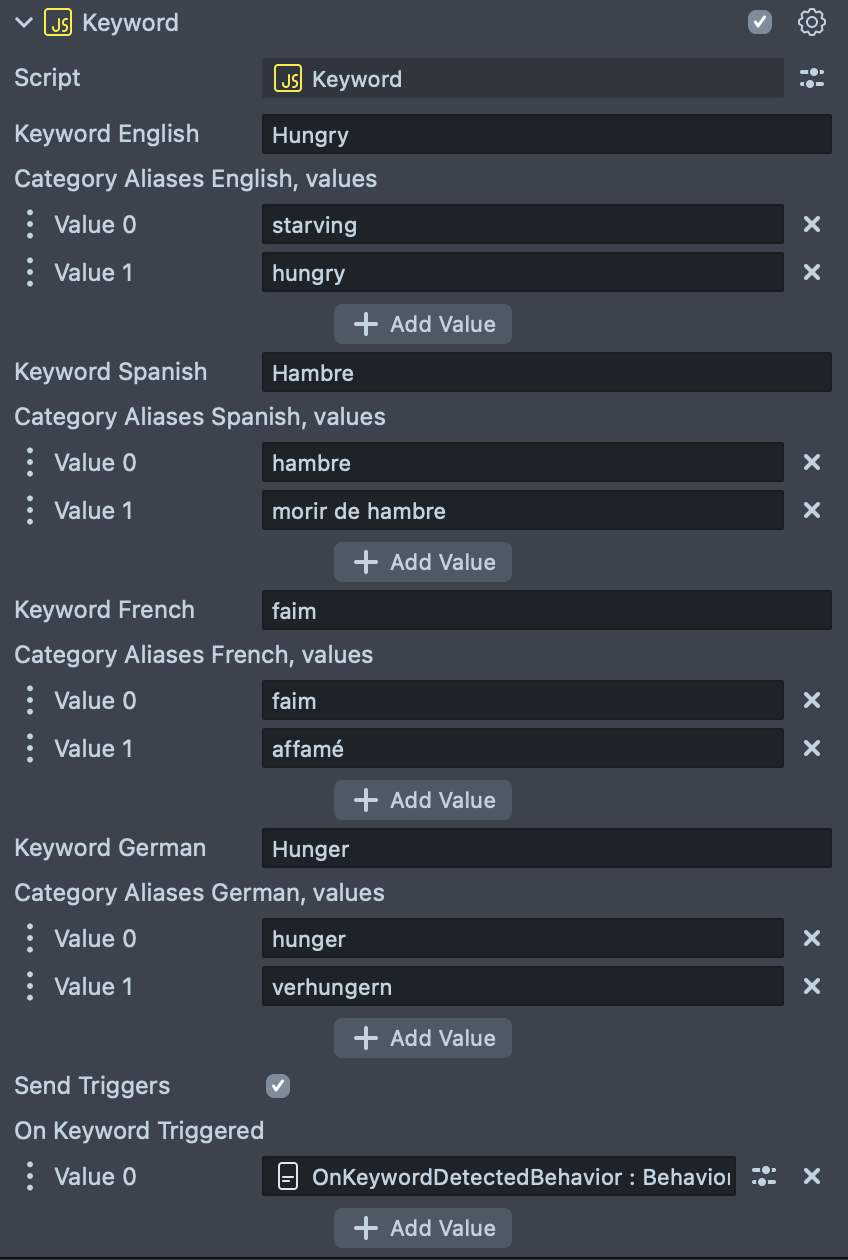
Now try resetting the Preview panel and with the Microphone button enabled in the Preview panel, try to say the words which are not from the keyword list. We can then see the keyword error messages in the Logger.
System Command and Intent Models
Voice Command Detection is based on basic natural language processing on top of transcription. Currently English is supported.
- Use Command: allows to handle commands and configure intent models.
- Intent Models: array containing intent model names. You may find more info about different intent models in this guide. Here are some possible options:
- VOICE_ENABLED_UI:
- EMOTION_CLASSIFIER: Allows to detect and emotion such as Anger, Disgust, Fear, Joy, Sadness or Surprise.
- YES_NO_CLASSIFIER: Allows to detect positive or negative intent.
- Command Handler: a reference to a CommandResultHandler script that allows to define responses for detected intents.
- Command Text: if enabled detected command can be displayed on a Text component.
- Text Component: Text component to set output text to.
- Intent Models: array containing intent model names. You may find more info about different intent models in this guide. Here are some possible options:
- Use System Voice Command: allows to use some of built-in system commands. Read more here.
Previewing Your Lens
You're now ready to preview your Lens! To preview your Lens in Snapchat, follow the Pairing to Snapchat guide.
Once the Lens is pushed to Snapchat, you will see hint: TAP TO TURN ON VOICE CONTROL. Tap the screen to start VoiceML and the OnListeningEnabled will be triggered. Press the button again to stop VoiceML and the OnListeningDisabled will be triggered.
